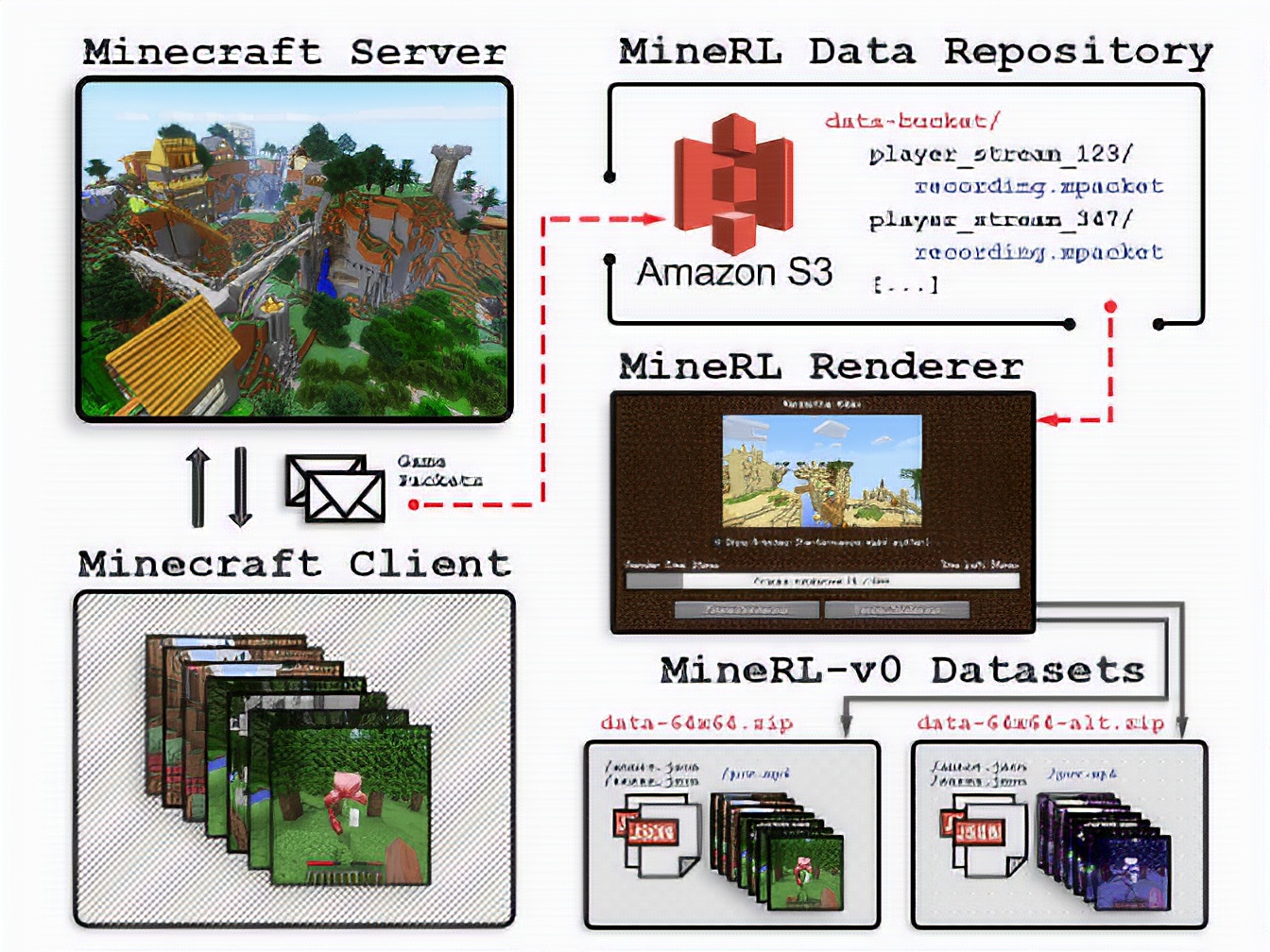
Who knew Minecraft offered such a rich training ground for AI and machine learning algorithms? Earlier this month, Facebook researchers posited that the hit game’s constraints make it well-suited to natural language understanding experiments. And in a newly published paper, a team at Carnegie Mellon describe a 130GB-734GB corpus intended to inform AI development — MineRL — that contains over 60 million annotated state-action pairs (recorded over 500 hours) across a variety of related Minecraft tasks, alongside a novel data collection scheme that allows for the addition of tasks and the gathering of complete state information suitable for “a variety of methods.”
“As demonstrated in the computer vision and natural language processing communities, large-scale datasets have the capacity to facilitate research by serving as an experimental and benchmarking platform for new methods,” wrote the coauthors. “However, existing datasets compatible with reinforcement learning simulators do not have sufficient scale, structure, and quality to enable the further development and evaluation of methods focused on using human examples. Therefore, we introduce a comprehensive, large-scale, simulator paired dataset of human demonstrations.”