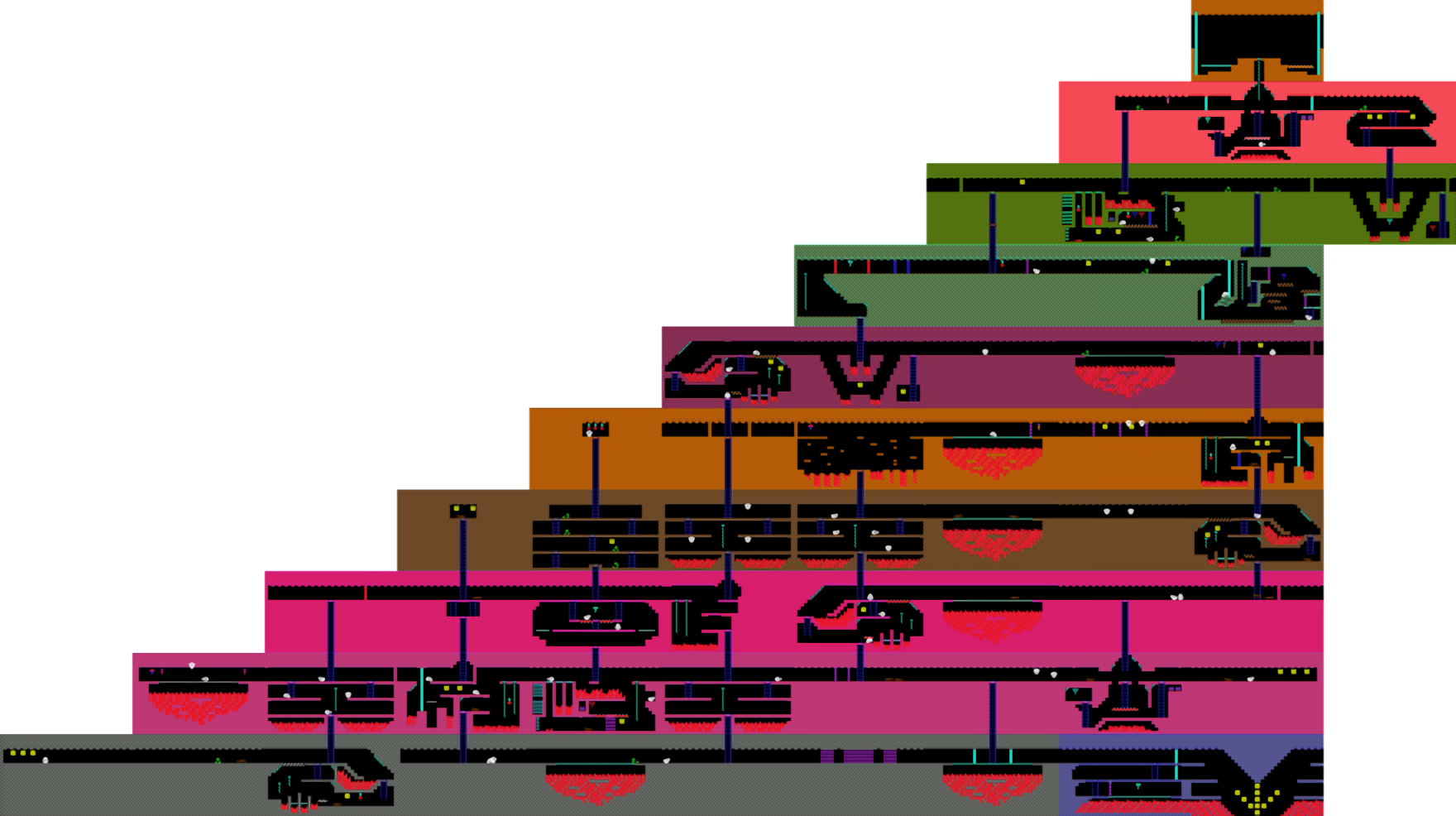
In 2015, Google subsidiary DeepMind published a landmark paper describing a system that could, given enough time and computational horsepower, learn to play a collection of Atari games like Breakout, Enduro, and Pong with superhuman proficiency. It failed to finish the more sophisticated Montezuma’s Revenge — a platformer that tasks players with avoiding laser gates, disappearing floors, fire pits, and other obstacles in pursuit of treasure — but AI systems have come a long way since then.
Case in point: A newly developed framework by researchers at RMIT University in Melbourne, which not only played Montezuma’s Revenge quite skillfully but which managed to learn from its mistakes in-game and identify subgoals (like climbing ladders and jumping over pits) 10 times faster than DeepMind’s original algorithm. The work (“Deriving Subgoals Autonomously to Accelerate Learning in Sparse Reward Domains”) is scheduled to be presented at the ongoing Association for the Advancement of Artificial Intelligence conference in Hawaii on Friday.